Intro
올해 MMT에 이직하고나서, 처음 알게된 nosql개념과 elasticsearch에 대해서 좀 더 자세하게 알고 싶어서, 사내에서 진행해온 스터디가 얼마전에(한달반만에) 끝이났다.
교재는 Elasticsearch in Action을 사용했고, 매주 화, 금에 진행했다.
책에는 elasticsearch 버전이 2.x으로 설명되어 있지만, 실습을 위한 elasticsearch 및 kibana 버전으로는 6.4.0을 사용했고, 버전에 따른 차이점은 그떄그때 기록했다.
책에서는 주로 elasticsearch의 핵심내용과 개념을 중점으로 스터디하려고 노력했다.
실습은 참여한 스터디원들의 성향에 따라 로컬에 직접 설치해서 진행한 사람도 있고, 나는 개인적으로 docker-compose를 이용했다.
스터디 자체에 대한 보다 자세한 내용과 진행은 Elasticsearch-Study 레파지토리에 기록했다.
이 포스트는 스터디를 진행하면서, 노트했던 내용들을 기록 목적으로 남기기 위함이다.
Note
Ch 1~2 Introducing Elasticsearch, Diving into the functionality
Understanding Elasticsearch Basic 라는 제목으로
사내 발표를 진행했었는데, 이때 교재의 1~2 챕터를 커버했다. elasticsearch의 핵심적인 내용, 특성, 샤딩, 언제 사용해야 하는지 등에 대해서 개괄하는 내용을 담고있다.
Ch 3 Indexing, updating, and deleting data
Data types
- Core—These fields include strings and numbers.
- Arrays and multi-fields—These fields help you store multiple values of the same core type in the same field. For example, you can have multiple tag strings in your tags field.
- Predefined—Examples of these fields include _ttl (which stands for “time to live”) and _timestamp
-> ttl을 써서 redis처럼 휘발성있게 사용할 수 있는듯, 다른 db도 ttl기능이 있나?
DEFINITION of “term”
A “term” is a word from the text and is the basic unit for searching.
In different contexts, this word can mean different things: it could be a name,
for example, or it could be an IP address. If you want only exact matches on a
field, the entire field should be treated as a word
Default analyzer의 indexing
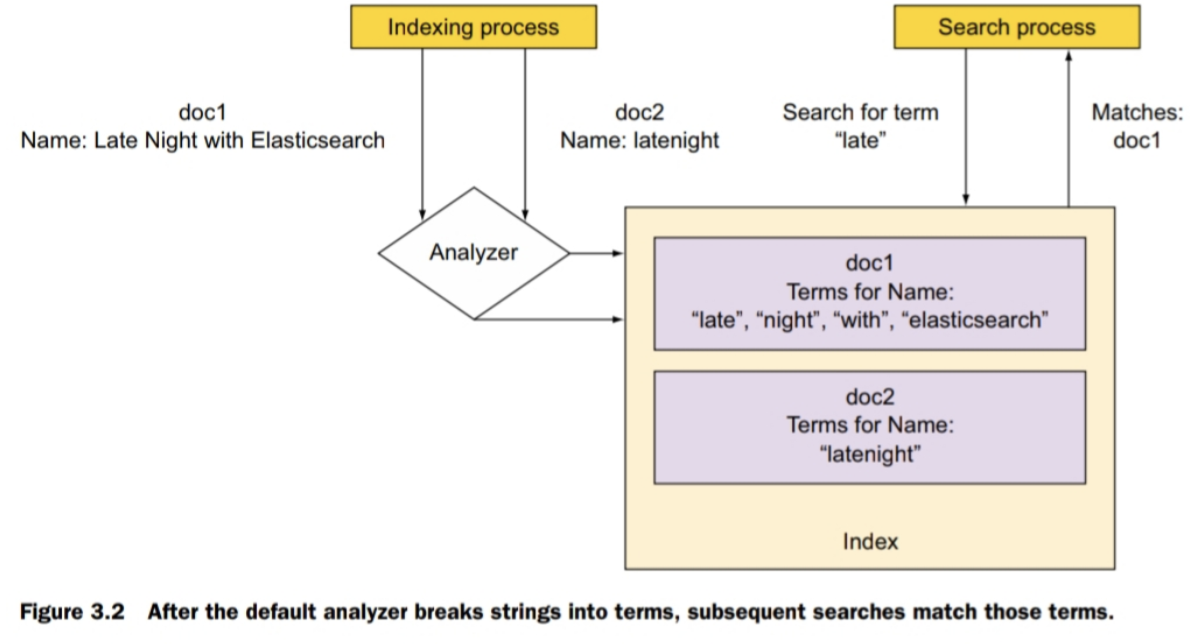
Setting index to not_analyzed does the opposite: the analysis process is skipped,
and the entire string is indexed as one term. Use this option when you want exact matches,
such as when you search for tags.
-> mapping의 field type의 index를 not_analyzed로 셋팅하면 doc이 index될때 전체 입력을 하나의 term으로 만들어주고 결과적으로 exact match가 되게된다
-> mapping의 field type의 index를 no로 셋팅하면 해당 필드는 doc이 index될때 아예 indexing 프로세스에서 제외된다(전체 indexing시간을 줄이는 효과를 가져온다
Ch 4 Searching your data
search 사용; 다중 index 및 다중 field 지정
curl 'localhost:9200/*/event/_search' -d '...'
curl 'localhost:9200/get-together,other/event,group/_search' -d '...'
curl 'localhost:9200/+get-toge*,-get-together/_search' -d '...'
search시 sort하면, score는 null로 평가된다
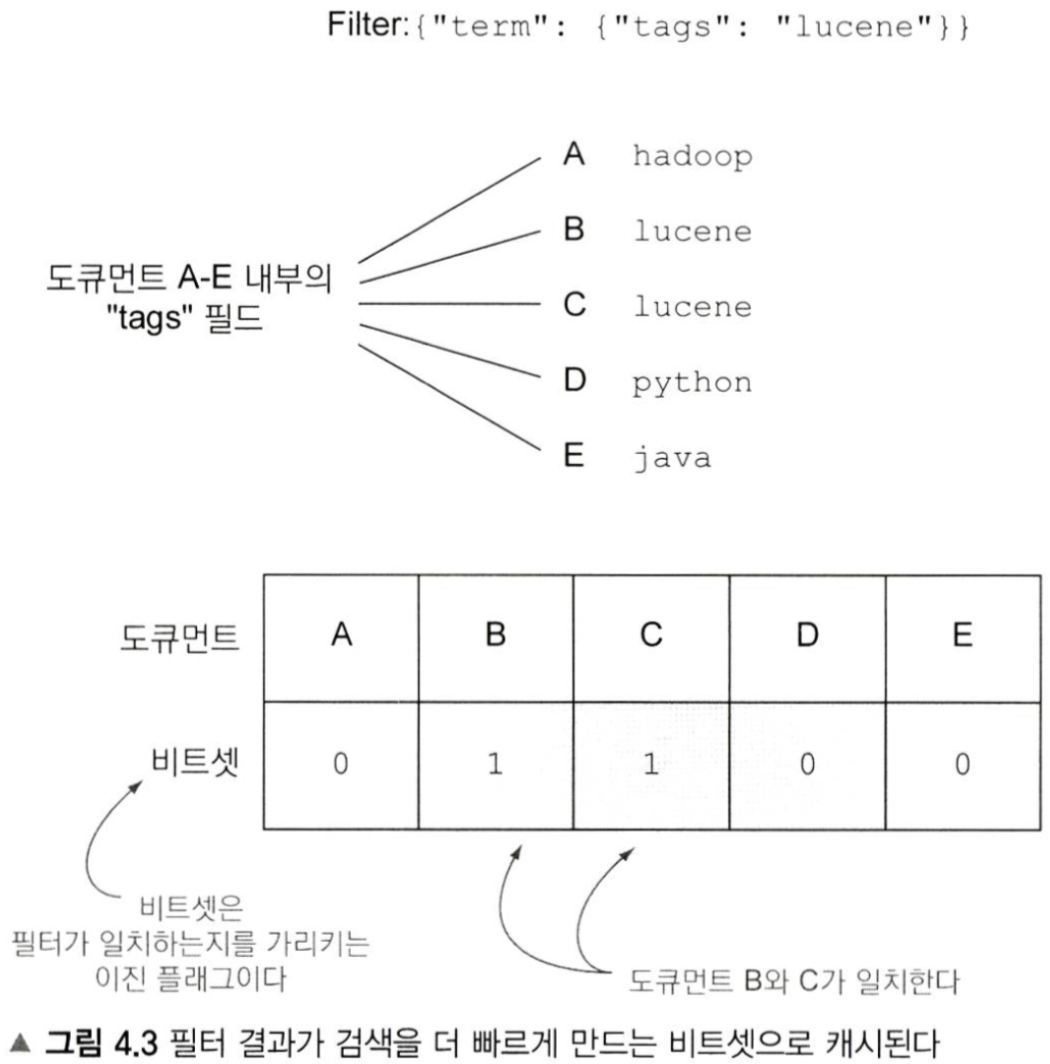
필터와 쿼리의 가장 큰 차이는 scoring! 필터는 scoring이 아니라 yes/no로 이진 판단만 한다
필터 비트셋 예시
Ch 5 Analyzing your data
분석기 동작 과정(도큐먼트가 indexing 되는 과정)
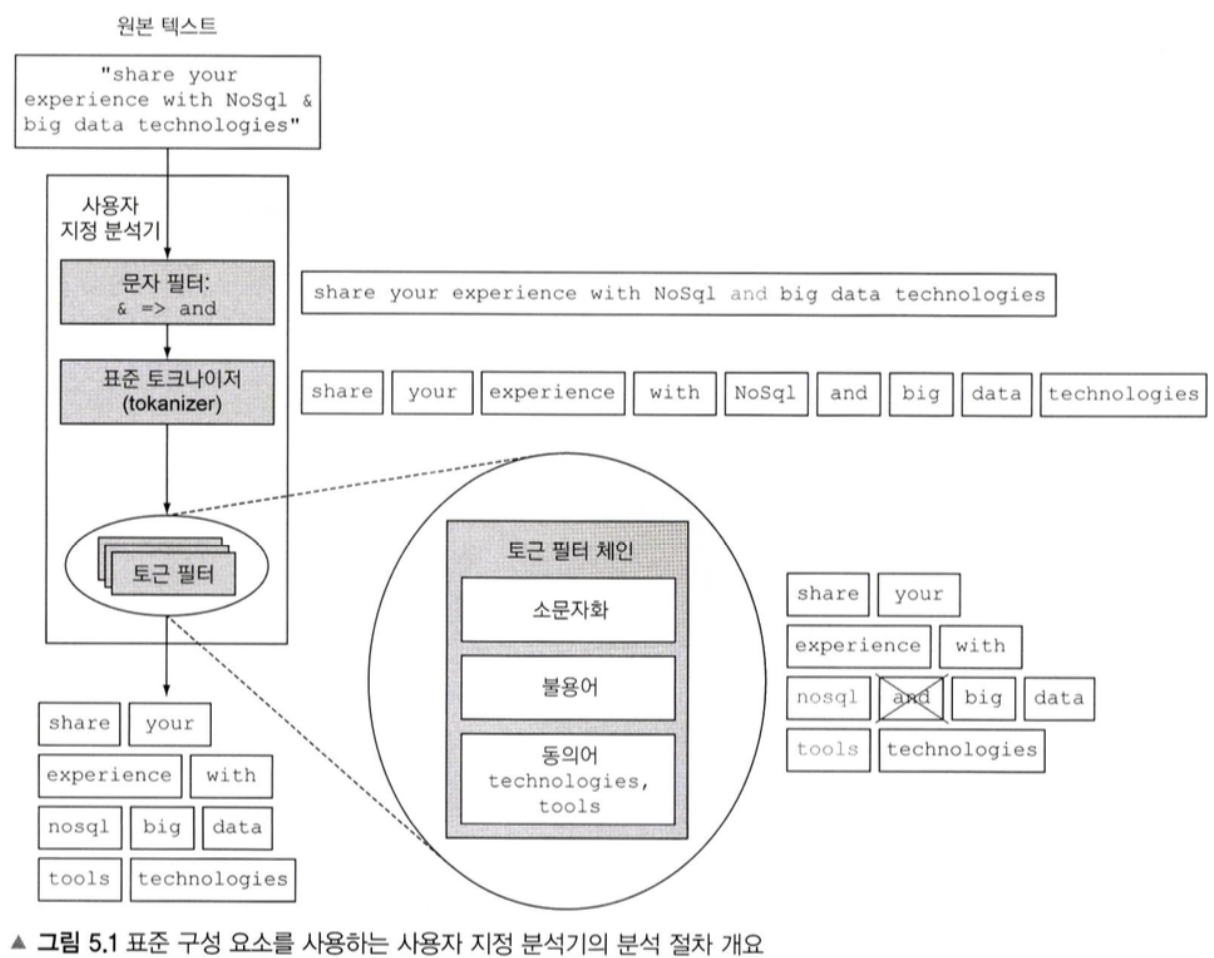
pattern, UAX/URL/EMAIL, path 토크나이저 유용할듯
Ngram 토큰필터; 토큰을 여러종류의 subtoken으로 재구성해서 indexing하는 원리
Shingle필터; Ngram과 비슷하지만 텍스트에서 토큰단위로 indexing을 한다
Ngram은 token -> subtokens, Shingled은 text -> tokens
스테밍과 그리고 필요에 따라 스테머를 오버라이드하여서, 어떤 단어는 어간만 남기지 않도록 할수도 있다
Summary
- 분석은 도큐먼트의 필드에 있는 텍스트를 토큰으로 만드는 과정이다. 같은 과정이 match 쿼리 같은 쿼리의 검색 문자열에도 적용된다. 도큐먼트의 토큰이 검색 문자열로부터의 토큰과 일치할 때 그 도큐먼트는 일치한다.
- 매핑을 통해 개별 필드에 분석기를 할당한다. 그 분석기는 일래스틱서치 설정이나 색인설정에 의해 또는 기본 분석기 설정으로 정의한다.
- 분석기는 하나 이상의 문자 필터가 하나 이상의 토큰 필터가 되는 토크나이저에 의해 만들어지는 체인을 처리한다.
- 문자 필터는 토크나이저로 보내기 전에 문자열을 처리하는 데 사용된다. 예를들어 “&”를 “and”로 변경하는 매핑 문자 필터를 사용할 수 있다.
- 토크나이저는 문자열을 다수개의 토큰으로 분해하는 데 사용할 수 있다. 예를들어, 화이트스페이스 토크나이저는 공백으로 개별 단어를 구분해서 토큰을 만드는 데 사용한다.
- 토큰필터는 토크나이저로부터 오는 토큰을 처리하는 데 사용한다. 예를들어, 어근으로 단어를 줄이고 단어의 복수와 단수 버전 둘 다 동작하는 검색을 만드는 데 스태밍을 사용할 수 있다.
- Ngram 토큰 필터는 단어 일부로 토큰을 만든다. 예를들어, 매번 두 개의 연속하는 문자를 토큰으로 만들 수 있다. 이는 검색 문자열이 오자(typo)를 포함 하더라도 동작하는 검색이 필요하다면 유용하다.
- Edge ngram은 ngram과 비슷하지만 오직 단어의 시작 또는 마지막으로부터 처리한다는 것이 다르다. 예를들어, “event”으로 e, ev, eve 토큰을 만들 수 있다
- Shingle은 ngram과 구(Phrase) 수준에서는 닮았다. 예를들어, 구에서 매번 연속하는 두 개의 단어로 텀을 생성할 수 있다. 이는 제품의 요약 설명에서처럼 다중-단어 일치에 대해 적합성을 높이려 할 때 유용하다.
Ch 7 Exploring your data with aggregations
집계(Aggregations) 종류
- 집계공통
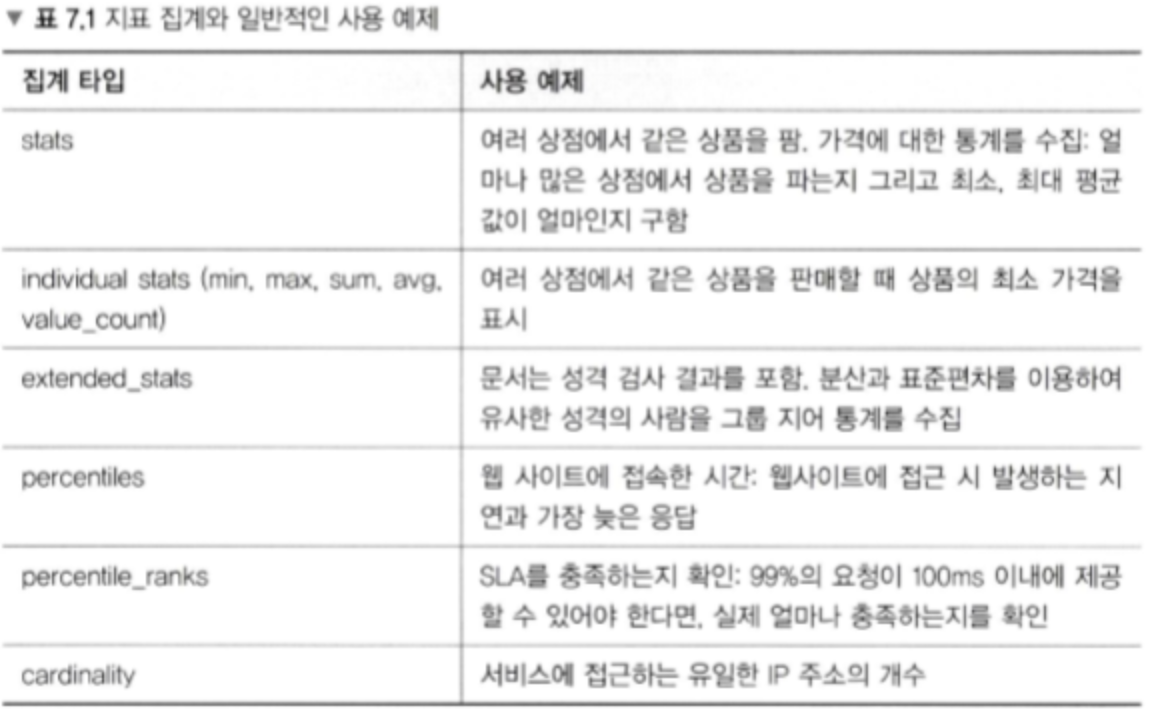
- 지표집계(metric aggregation) - 통계분석(최대, 최소, 표준편차 등)
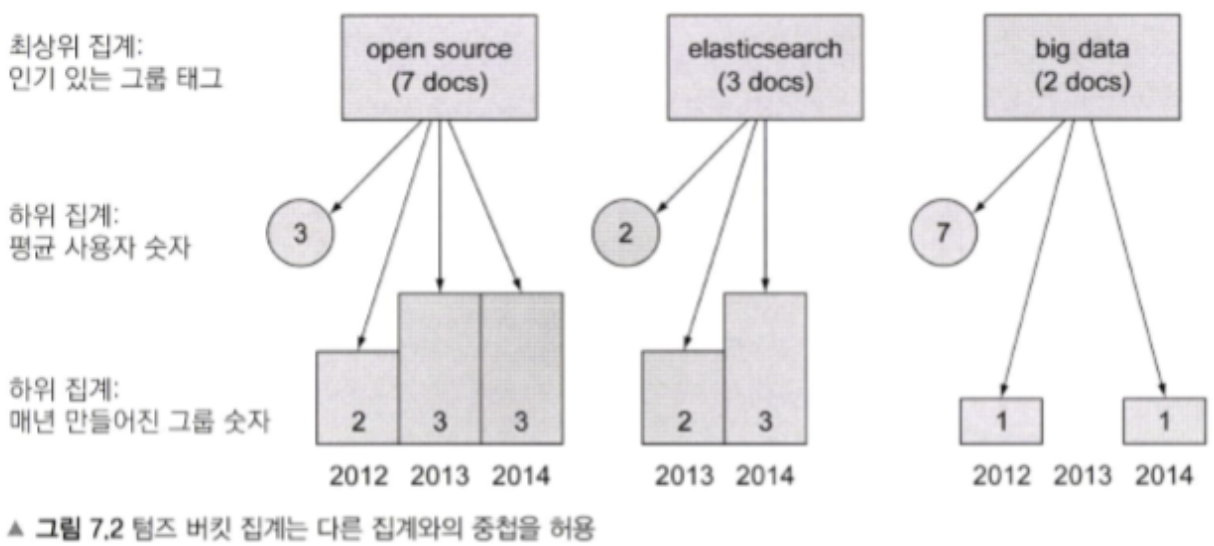
- 버킷집계(bucket aggregation) - 그림 7.1에서 각 tag들이 하나의 버킷에 해당되고, 그 버킷에 문서가 담긴다

- 중첩집계(composite aggregation) - 그림 7.2처럼 버킷아래에 또 다른 기준의 집계를 위한 하위 버킷을 중첩해서 사용할 수 있다
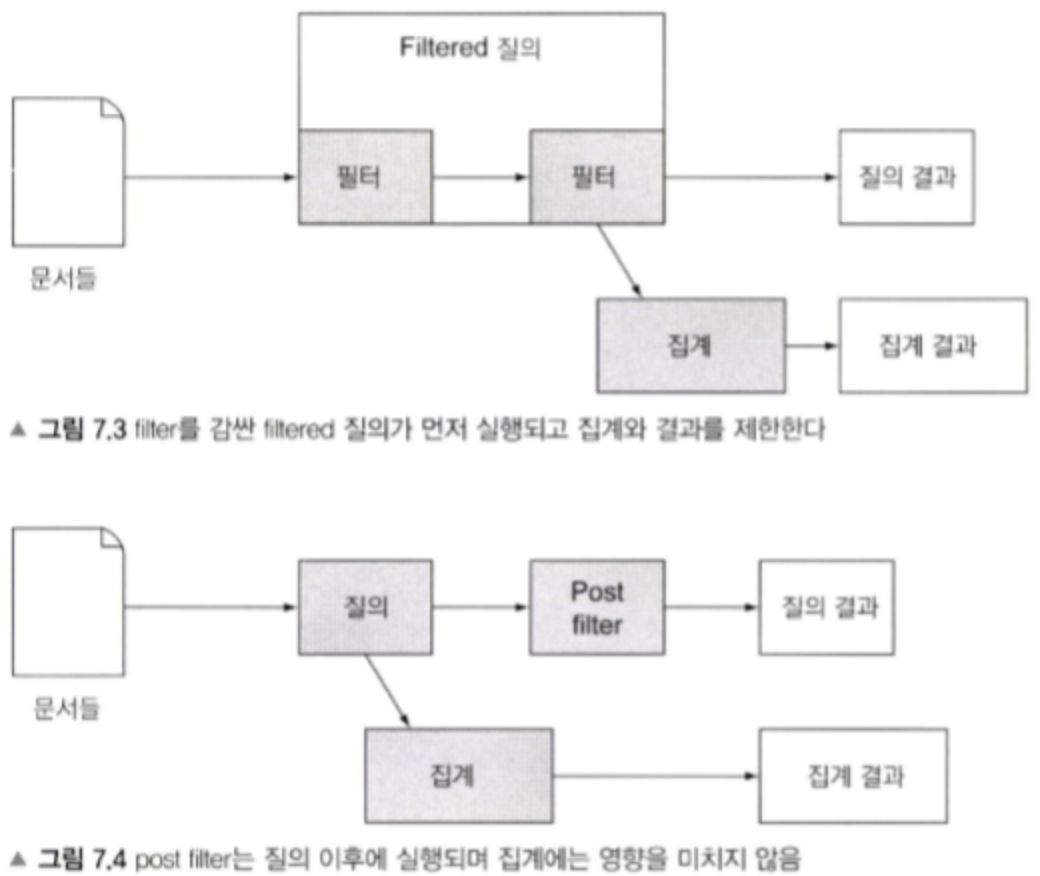
Filtered 질의와 post filter의 비교
근사치통계(approximate aggregations)의 필요성
-> 문서 전체를 대상으로하는건 많은 시간과, 메모리를 사용한다
- 메모리 - 유일한 단어를 계산하기 위해 메모리에 모든 단어가 적재되어야 한다.
- CPU - 결과는 정렬되어 보여야 한다. 기본적으로 순서는 각 용어가 발생한 횟수로 정렬된다.
- 네트워크 - 각 샤드에서 유일한 단어로 정렬된 큰 배열이 사용자의 요청을 받은 노드로 전송되어야 한다. 그리고 전달받은 노드는 사용자에 게 값을 반환하 기 위하여 전달받은 큰 배열을 하나의 배열로 합치는 작업을 진행해야 한다.
근사치통계(approximate aggregations)의 종류
- percentiles -> aggregation하려는 문서를 백분위화 해서 그 값으로 aggregation하는 것
- cardinality
지표집계(metric aggregation) 예제
버킷집계(bucket aggregation)의 종류
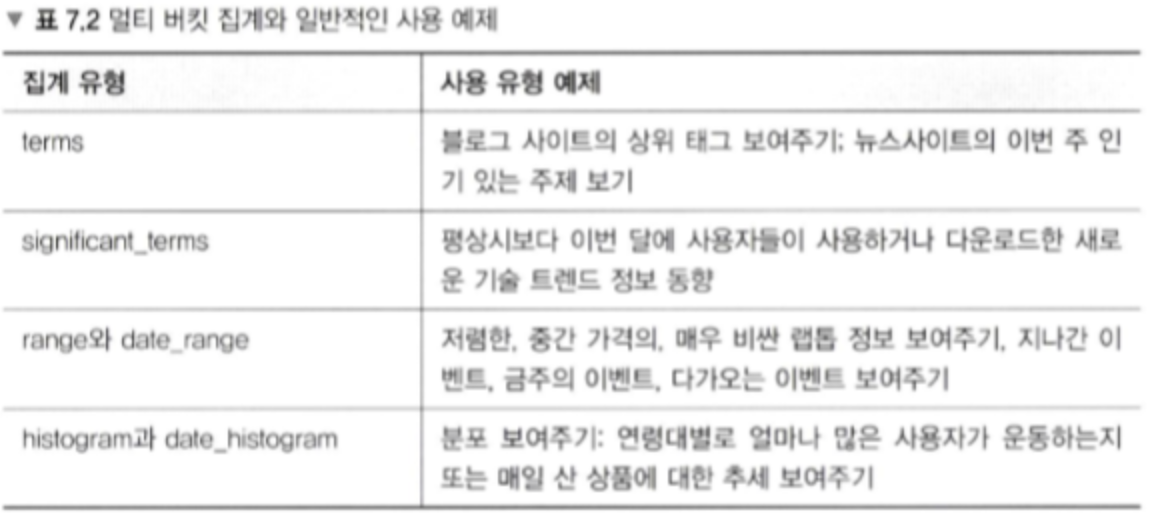
- terms aggregation(significant terms aggregation)
- range aggregation -> 범위의 최솟값은 포함되나, 최대값은 포함되지 않는다
- histogram aggregation
- 문서의 관계와 관련있는 집계, nested, reverse-nested, parent-child aggregation
- geodistance, geohash grid aggregation
버킷집계(bucket aggregation 예제
missing aggregation; nosql의 특징을 잘 회피하면서 aggregation 하는 유용한 방법인 듯
Summary
- 집계는 결과 문서로부터 단어를 계산하고 통계를 계산하여 질의 결과의 전체 적인 정보를 얻는 데 도움이 된다.
- 집계는 버킷과 지표의 2가지 주요 유형이 있다.
- 지표집계는 숫자 필드의 최소, 최대, 평균과 같이 문서의 집합에 대한 통계를 계산한다.
- 일부 지표집계는 정확한 값보다 확장성을 위해 근사치 알고리즘을 이용하여 계산된다. percentiles, cardinality 집계가 여기에 속한다.
- 버킷집계는 하나 또는 그 이상의 버킷에 문서를 넣고 이 버킷에 계산된 결과를 돌려준다. 예를들어 포럼에서 가장 인기있는 게시글을 찾는다고 하자. 버킷집계 밑에 버킷집계에서 생성된 각 버킷에 한 번 동작하는 하위집계를 중접하자. 이 중첩집계를 이용하여 각 태그에 일치하는 포스트의 평균 댓글 수를 알 수 있다.
- top hits 집계는 하위 집계의 결과를 묶어서(grouping) 보여줄 수 있다.
- 텀즈집계는 일반적으로 상위 유저/위치/상품과 같은 정보를 얻기 위해 사용한다.
- significant terms 집계와 같은 텀즈집계의 변형인 다중 버킷 집계는 전체 색인보다 질의 결과에 의해 자주 나타나는 단어를 반환한다.
- 범위 / 날짜 범위 집계는 숫자와 날짜 필드를 범주화할 때 유용하다.
- 히스토그램 / 날짜 히스토그램 집계도 유사하지만, 날짜 범위를 지정하는 대신 날짜 간격을 이용한다.
- global, filter/filters, missing 집계와 같은 단일 버킷 집계는 질의의 결과로 문서를 반환하며,
다른 집계가 실행하는 문서집합을 변경하는 데 사용 된다.
Ch 8 Relations among documents
elasticsearch에서 도큐먼트간 관계를 다루는 방법들
- 개체(Object) datatype
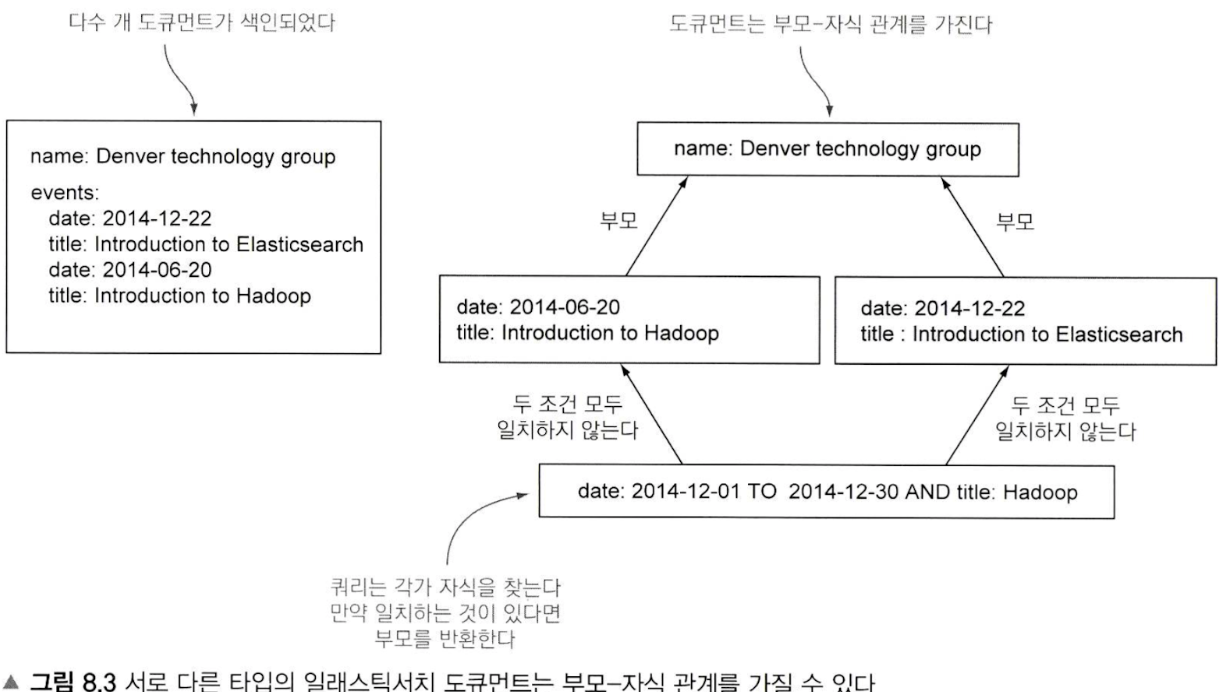
- 중첩(Nested) datatype
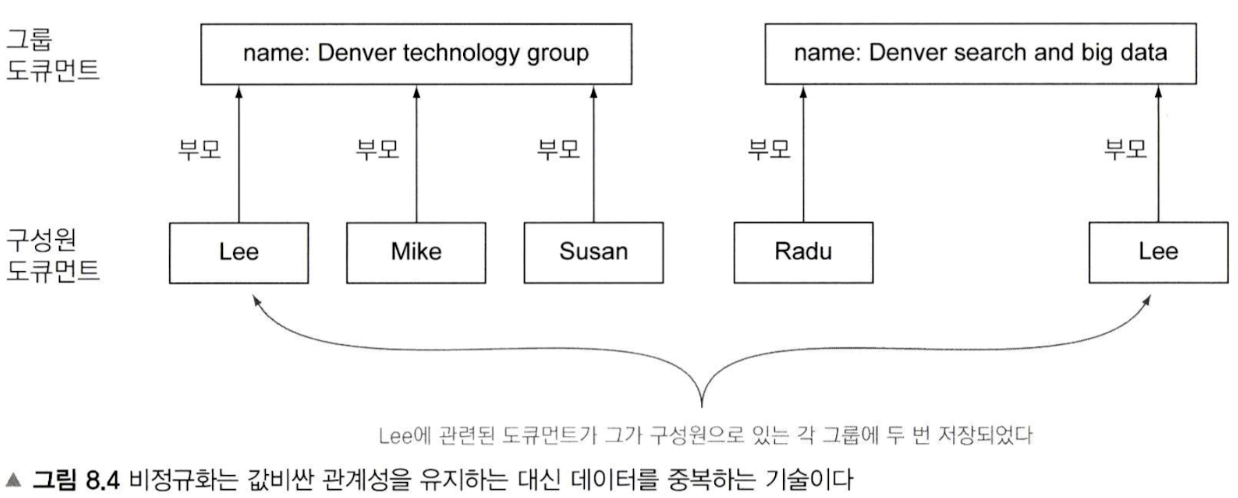
- Parent/child(-> join datatype으로 대체됨)
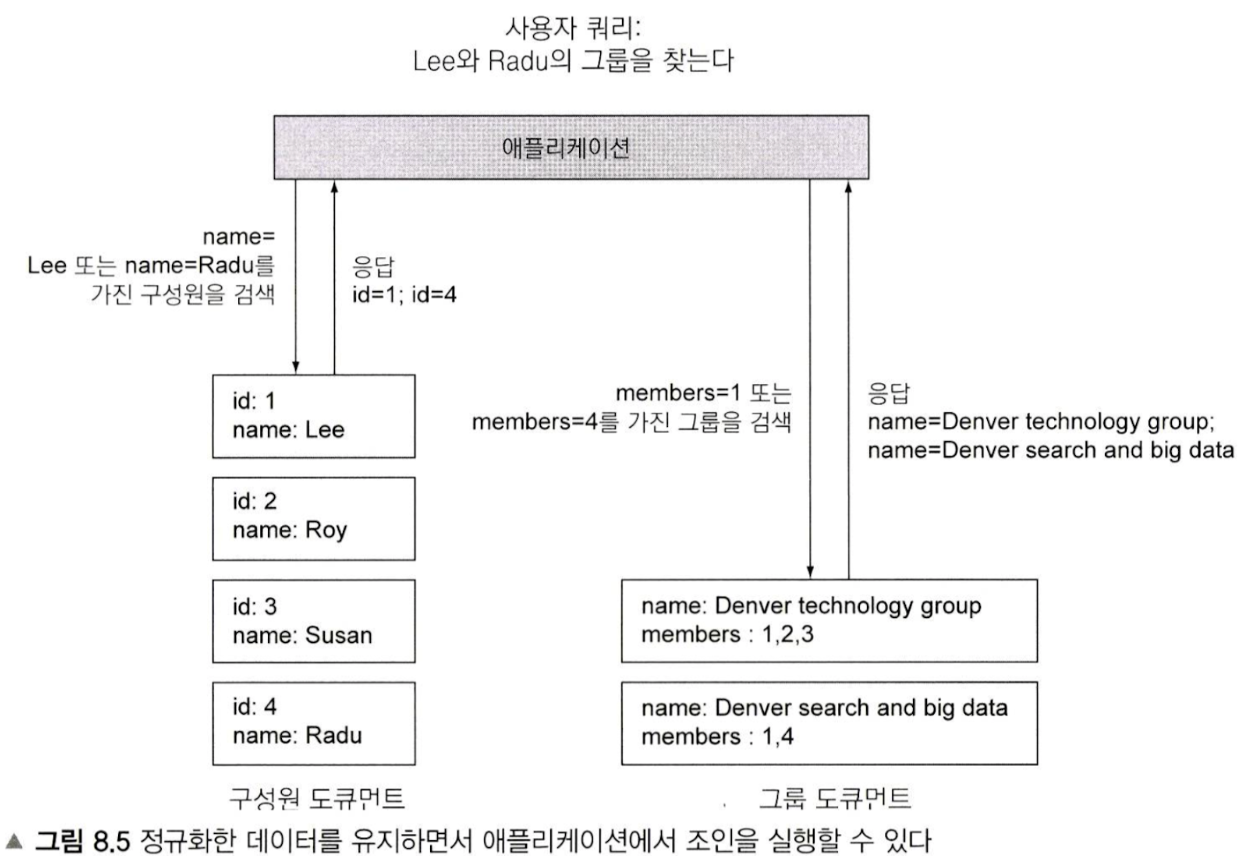
- 비정규화(Denormalize)
- 개별 Document, App level에서 logic으로 처리
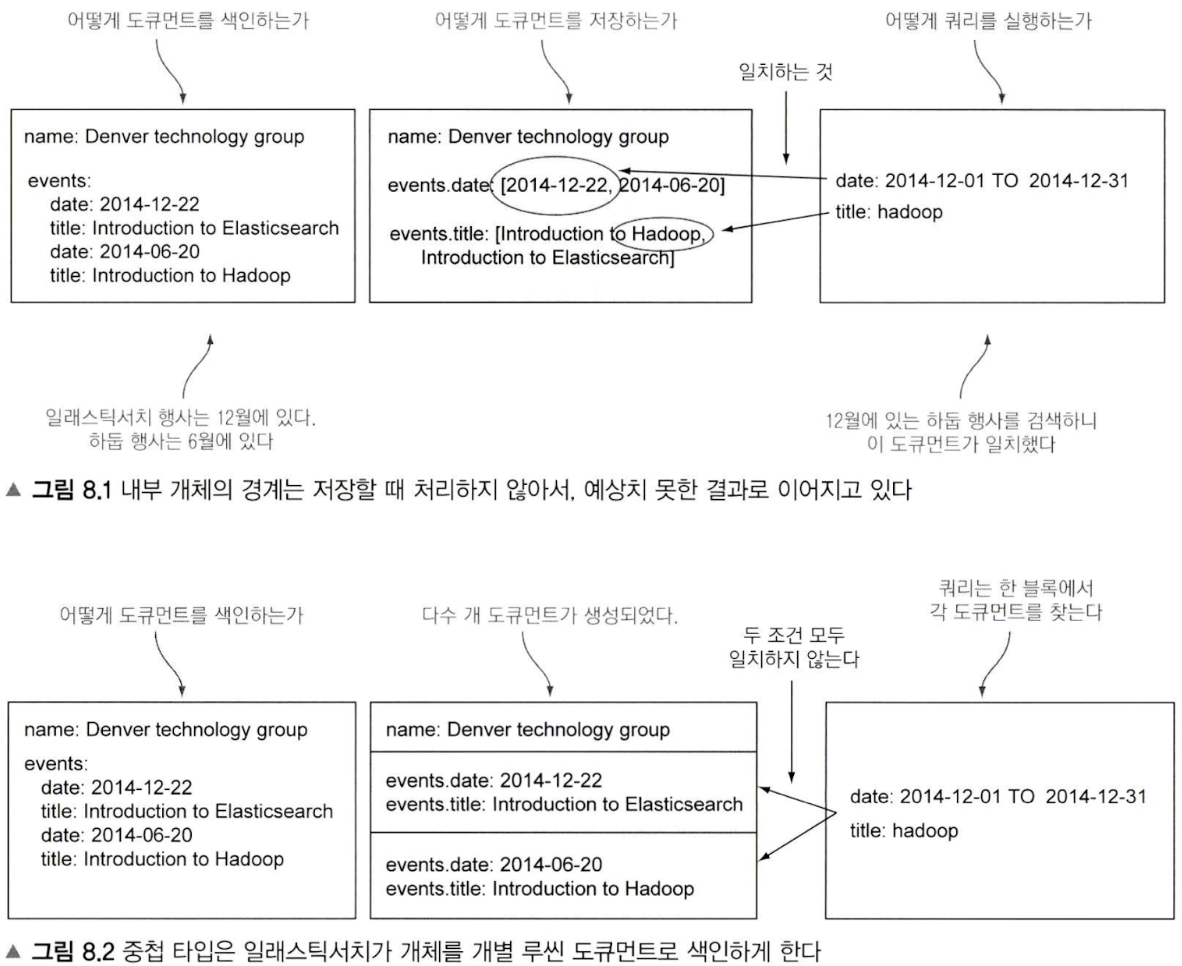
개체(Object) datatype의 도큐먼트를 indexing 하는 경우, 내부 저장구조

개체(Object) datatype은 1:1관계에서 가장 잘 작동한다, 1:N을 표현하기 위해서는 data indexing을 array로 해야하는데, 이렇게 되면 elasticsearch는 내부적으로 아래와 같이 indexing 하게되어 예상치 않은 동작을 한다.

개체(Object) datatype에서 교차-개체 조건을 둘다 활성화 하려면, INCLUDE_IN_ROOT, INCLUDE_IN_PARENT를 사용해야한다
- INCLUDE_IN_ROOT 예시

- INCLUDE_IN_PARENT 예시

Ch 9 Scaling out
노드 1개에서 -> 2개로 scale out되는 경우 동작; unassigned 되어있던 샤드들이 assign 된다
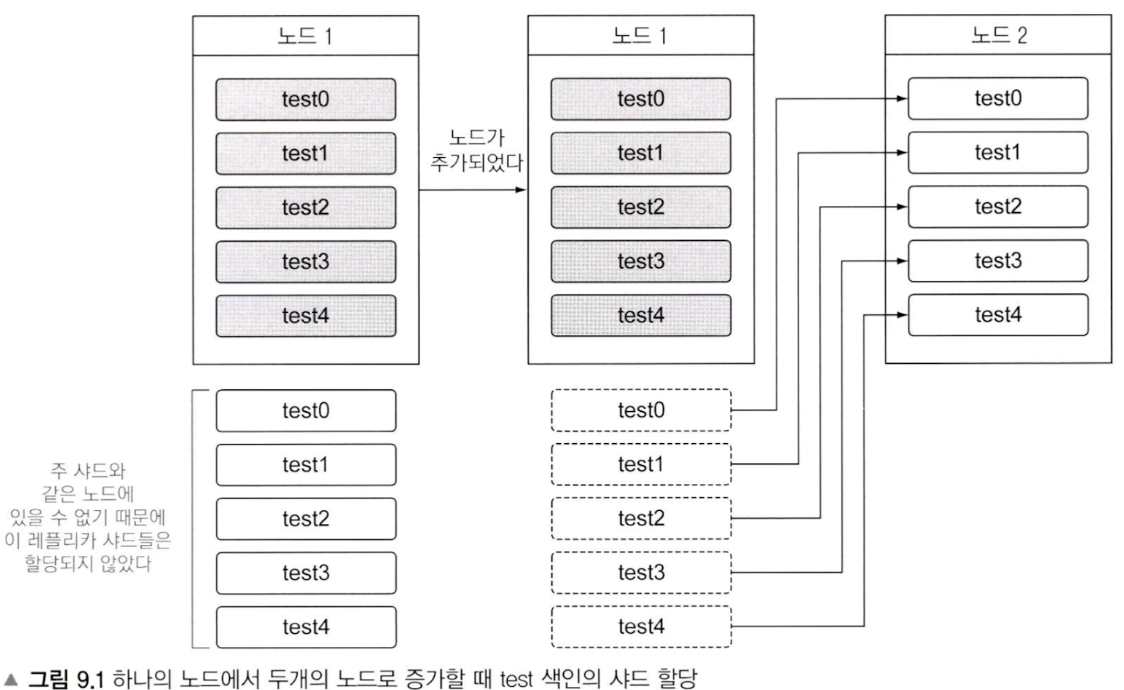
그림 9.2처럼, 노드가 3개일때 한 노드에 primary, replica 샤드가 동시에 있을 수는 있지만 같은(같은 번호의) primary, replica 샤드가 동시에 같은 노드에 있을 수는 없다
es는 primary 샤드를 찾을 수 없을 경우, replica샤드를 primary로 승격시켜서 사용한다
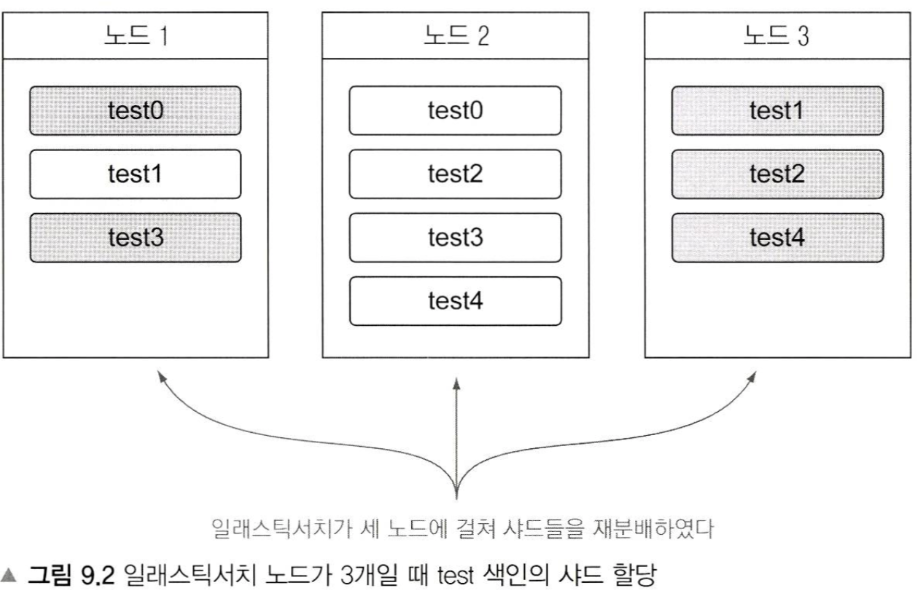
노드가 추가되면 좋은 점
query나 aggregation 성능 향상에 도움이 된다(각 노드별로 메모리 및 연산 리소스를 따로 사용하기 분산처리 효과가 있음)
노드 디스커버리
es에서 노드 멀티캐스트 디스커버리는 deprecated 됐다. 유니캐스트 디스커버리는 미리 elasticsearch.yaml에 config 해둔 hosts들만에 네트워킹해서 노드들을 서로 발견한다.
디스커버리 단계이후(클러스터 내 모든 노드들이 파악된 이후) 마스터 노드를 선출한다
마스터 노드
- 마스터 노드는 다른 노드들의 장애를 감지하고, 클러스터의 상태(설정값, 샤드, 색인, 노드들의 상태)를 관리하는 역할
- 모든 노드들은 기본값으로 마스터 노드가 될 수 있는 config 값을 갖는다(node.master = true가 기본)
- 클러스터 config에 minimum_master_nodes값을 설정해서, 마스터노드가 될 수 있는 후보의 갯수를 설정할 수 있는데,
노드 수가 고정되어 있다면 이를 전체 노드의 갯수로, 노드 수가 동적이라면, (전체 노드 수 + 1) / 2로 해야 스플릿 브레인 현상을 막을 수 있다
예를들면, minimum_master_nodes 값이 6이고 노드가 10개인 클러스터 구성이라면, split brain을 방지할 수 있다
클러스터의 노드들에 장애가 올때, 최소 클러스터 구성 조건이 6이므로, 6개 노드가 있는 새로운 클러스터가 생성되고, 기존 4개의 노드들이 새로 생성된 클러스터에 join 되어서 스플릿 브레인이 방지된다
만약 minimum_master_nodes 값이 5라면, 5개의 노드로 구성된 클러스터가 2개가 새로 구성될 수 있는데, 이런 현상이 split brain이다. - 스플릿 브레인?
클러스터 내의 일부 노드들이 마스터 노드와 핑을 통해 통신하지 못해서 장애라 판단하고, 마스터 노드를 새로 선출해서 클러스터 내의 여러 마스터 노드가 발생해서 각각의 클러스터가 동작하고 있는 상황 - 마스터 노드의 선출은 어떻게? -> 선거, voting 로직이 있음
마스터 노드의 장애감지 프로세스
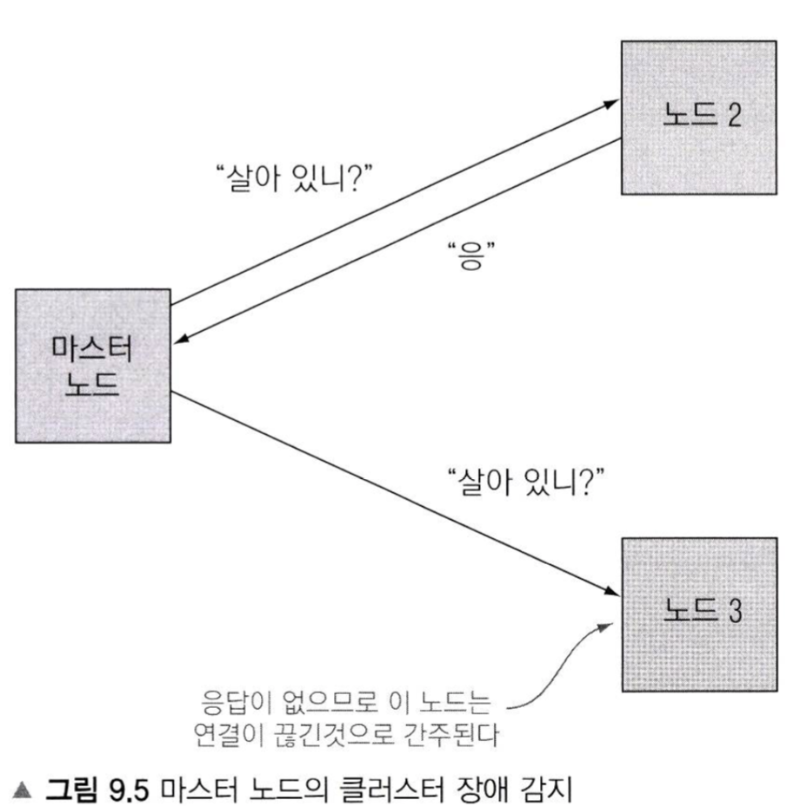
장애감지 프로세스 config 값들
- ping_interval: 마스터 노드는 이 간격마다 다른 노드들에 장애 감지를 위한 핑을 보낸다
- ping_timeout: 마스터 노드는 이 시간동안 장애 감지를 위한 핑의 리스폰스를 기다린다
- ping_retries: 마스터 노드는 이 횟수만큼 타임아웃 된 리스폰스를 받아들인다
- 장애가 발생했다고 판단하면 -> 샤드를 재배치하거나 또는 마스터 노드를 재선출한다
예를들어 서로 다른 aws 리전에 있는 ec2들을 노드로 사용하는 것처럼 ping의 요청/응답 레이턴시가 긴 경우 위 config 값들을 적절하게 변경해줘야 한다
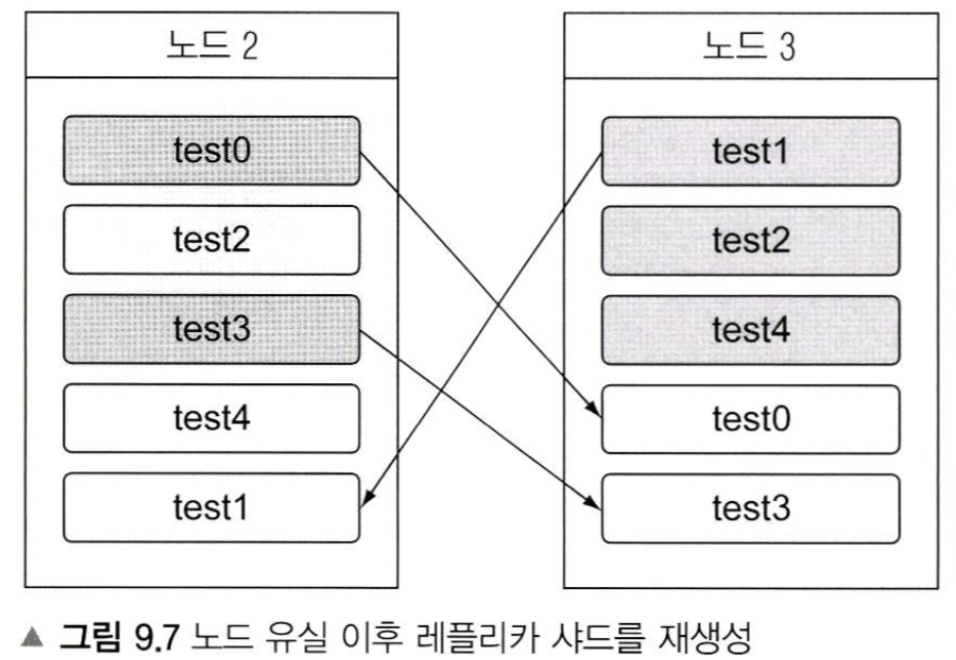
노드가 유실되는 경우 동작
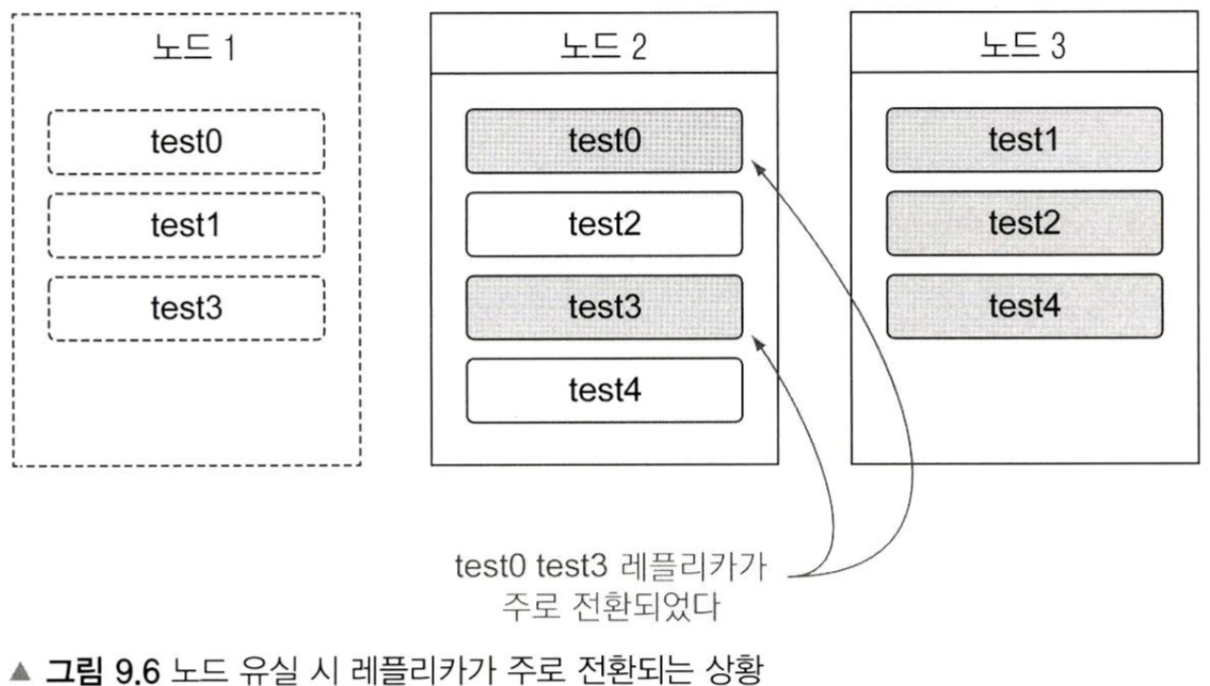
이후에, 레플리카 샤드를 재생성